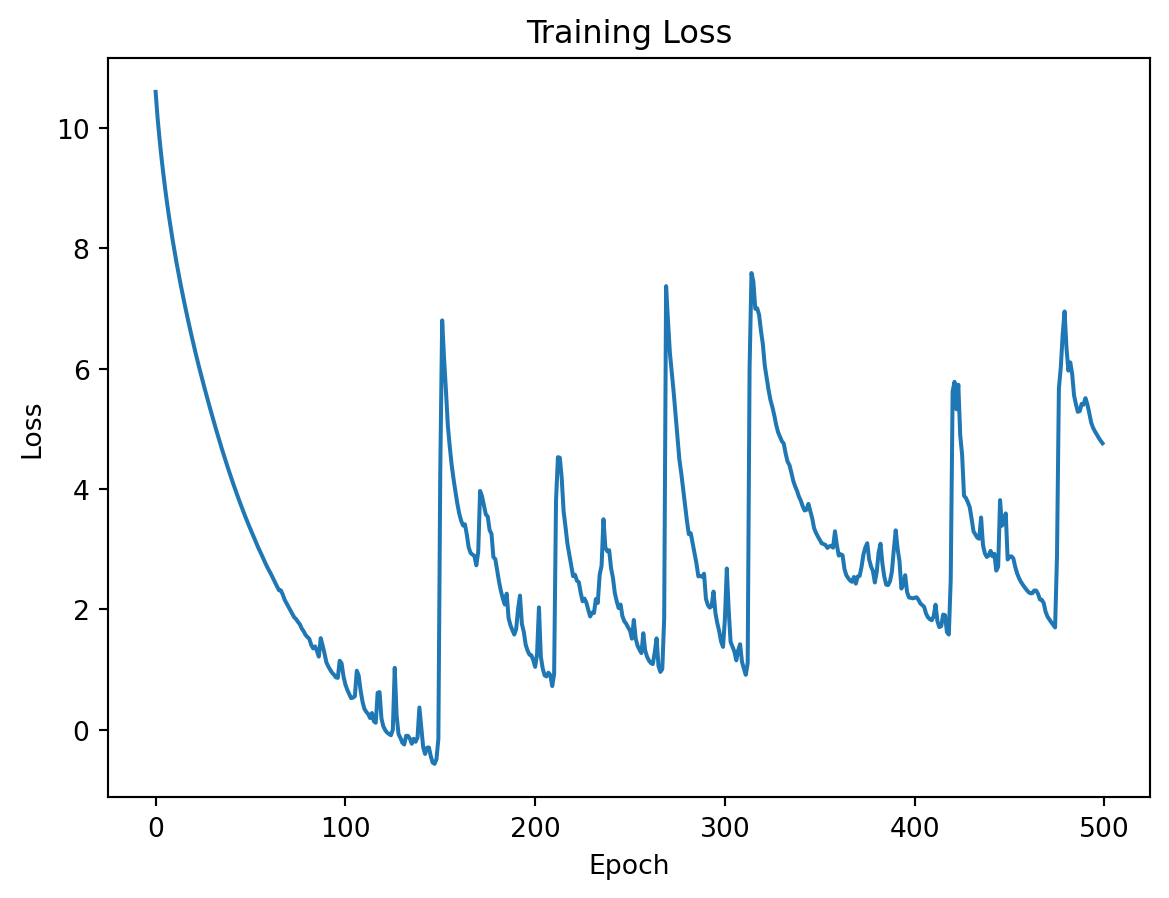
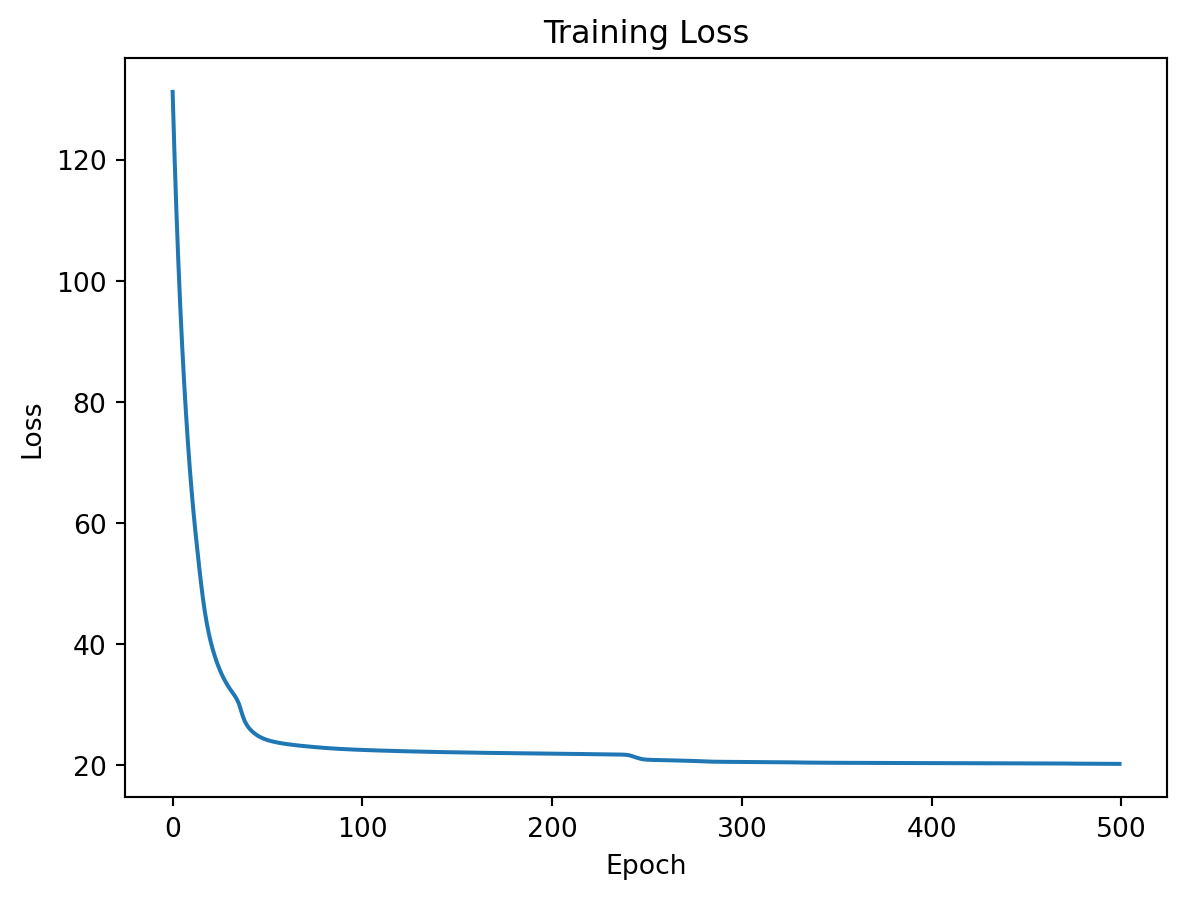
Discussion on implementation
For numeric stability, I cannot use the full range \([0, 1]\), thus it should be clamp to \([\epsilon, 1 - \epsilon]\).
For a reasonable range, \(\text{logit}(10^{-4}) \approx -9.2\). Thus I use \(\epsilon = 10^{-4}\).
Also, I don’t want range length to be compressed too small, thus I add a temperature \(\tau\):
\[
g(x) = \tau \log \frac{x}{1 - x}
\]
And I want (\(\rho\) denotes a range \([a, b]\)):
\[
\frac{|g(\rho)|}{|\rho|} = \frac{g(b) - g(a)}{b - a} \ge \text{Constant}
\]
A sufficient condition is (using Lagrange’s Mean Value Theorem):
\[
\forall x \in (0, 1), \,\, g'(x) \ge \text{Constant}
\]
Let constant be 1, we have:
\[
\forall x \in (0, 1), \,\, \frac{\tau}{x(1 - x)} \ge 1
\]
This yields that \(\tau \ge 0.25\). I choose \(\tau = 2.5\) for better resolution.